
Регулярные выражения, что это такое и с чем их едят?
Вступление
В этой статье я хочу рассказать о регулярных выражениях. Для непосвященного пользователя они сложны для понимания, поэтому постараюсь максимально просто, с примерами, показать для чего и как они используются в Zennoposter. Надеюсь, данная статья будет полезна для всех!
Регулярные выражения достаточно широко используются в программе, а именно:
- Для поиска элементов;
- Во время парсинга данных с веб-сайтов или из файла;
- Для удобства обработки данных из различных источников (замене или удалению фрагментов текста);
- При установке разделителей в списках и таблицах;
- Многое другое.
Регулярное выражение - это язык поиска подстрок в тексте, основанный на использовании специальных символов и указателей. По сути это строка-образец, которая состоит из символов (статического текста) и спецсимволов (символов, обозначающих какие-то последовательности) и задаёт правило поиска подстроки в обрабатываемом тексте.
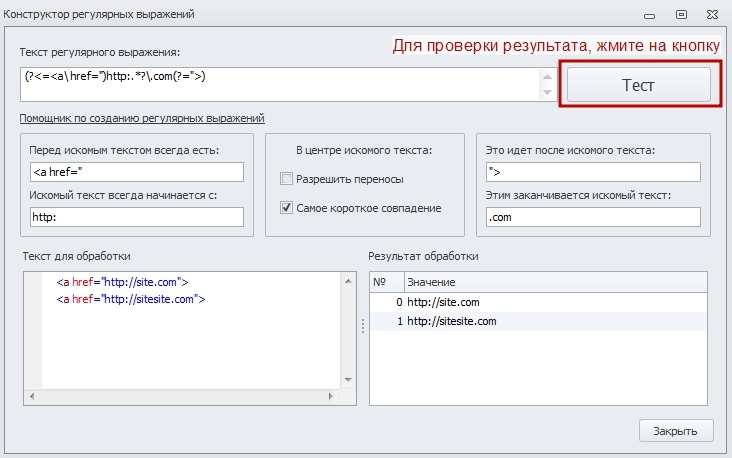
Для постройки регулярных выражений в программе есть специальный инструмент – «Конструктор регулярных выражений». В нём можно протестировать готовые выражения, а так же составить свои.

Возьмём текст и составим на его примере регулярное выражение так, чтобы получить домены сайтов:
a href="http://site.com">
a href="http://sitesite.com">
В Конструкторе есть раздельные поля - текст, который идет перед искомым (a href="), с которого начинается (http:), заканчивается искомый текст (.com), что идёт после него (">). В результате мы получим следующее регулярное выражение:
(?<=a\ href=")http:.*?\.com(?=">)
и список доменов в результатах тестирования.
Так же в Конструкторе имеется два чекбокса:
1) Разрешить переносы - включает и выключает поиск по тексту с учетом переносов строк (при включении данной опции, регулярное выражение не ограничено поиском в пределах одной строки, а так же учитывает переносы строк);
2) Самое короткое совпадение - включает и выключает поиск самого короткого совпадения. При включении данной опции, в результатах мы получим самую короткую подстроку, соответствующую составленному выражению. При выключении, соответственно - самую длинную.
При заполнении этих полей, Ваш текст автоматически преобразуется и в поле "Текст регулярного выражения" будет предоставлено готовое выражение, которое можно использовать для поиска.
Конструктор регулярных выражений, который есть в программе Zennoposter, достаточно не плох, но не универсален. Он подходит для составления простых выражений, когда мы имеем точные совпадения в тексте - что идет перед или после текста, который нам нужно найти, чем он начинается или чем заканчивается. Иногда, полученный результат бывает не удовлетворительным - строк больше или меньше, чем нужно, или просто вместо искомого текста мы получаем разный мусор. В таких случаях необходимы более широкие знания и правка выражений, сформированных Конструктором, вручную.
Для того, чтобы правильно самостоятельно составить регулярные выражения, рассмотрим основные символы, определим в какой ситуации они могут использоваться.
Символьные обозначения:
«.» - любой символ, кроме переноса строки(\n);
«\d» - цифровой символ, т.е. любая цифра от 0 до 9;
«[0-9]» - цифровой диапазон - отличается от \d тем, что в данном виде есть возможность указать не любой цифровой символ, а используя диапазоны, например [1-3], который найдет только цифры 1, 2 и 3;
«\D» - не цифровой символ. Т.е. все символы - буквенные и пробелы, кроме цифр;
«\s» -все пробельные символы, которые могут включать в себя:
- пробел «\ »;
- новая страница «\f»;
- возврат каретки «\r»;
- новая строка «\n»;
- знак табуляции «\t»;
- знак вертикальной табуляции «\v»;
«\S» - не пробельный символ, т.е. все буквы, цифры и знаки. Всё, что не перечислено выше, как пробельные символы.
«\w» - буквенный или цифровой символ или знак подчёркивания.
«\W» - любой символ, кроме буквенного или цифрового символа или знака подчёркивания.
Обозначения границ:
^ - начало строки;
$ - конец строки;
\b - граница слова;
\B - не граница слова.
К примеру, нам нужно проверить, содержит ли строка слово “Красный”, прописав в конструкторе «красный», мы можем получить так же и другие слова, в которые входит данное слово, такие как “прекрасный” и т.д. Что бы этого не происходило, необходимо прописать \bкрасный\b - таким образом, все слова, которые могут быть похожи на искомое учитываться не будут.
Не граница слова, соответственно, работает наоборот. К примеру, мы знаем, что слово должно заканчиваться на “жили”, но само слово “жили” нам не нужно, тогда мы прописываем \Bжили и получаем список слов с нужным нам окончанием - дорожили, выжили и т.д.
Обозначения количества совпадений (Квантификаторы):
{5} - ровно 5;
{1,5} - от 1 до 5 включительно;
{1,} - от 1 и более;
? - ноль или одно, так же соответствует {0,1};
* - ноль или более, так же соответствует {0,};
+ - Одно или более, так же соответствует {1,}.
Квантификаторы устанавливаются после символов, число повторений которых необходимо задать.
Возьмём для примера точку, которая обозначает любой символ, и составим регулярное выражение, которому будет соответствовать любая последовательность из 4 символов. Результат будет выглядеть таким образом: .{4}
Так можно указать, что внутри искомого текста имеется установленное или неограниченное число повторений установленных символов, т.е.:
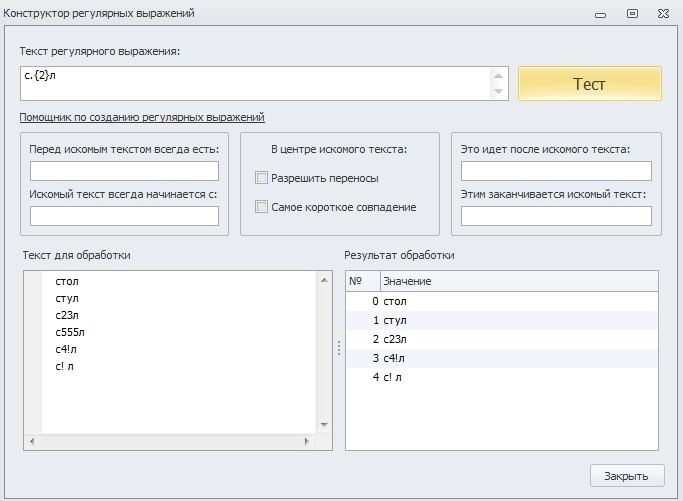
с.{2}л - такое регулярное выражение найдёт такие слова, как стол, стул и т.д., но ему так же будет соответствовать строка, имеющая в середине пробелы, цифры и прочее.
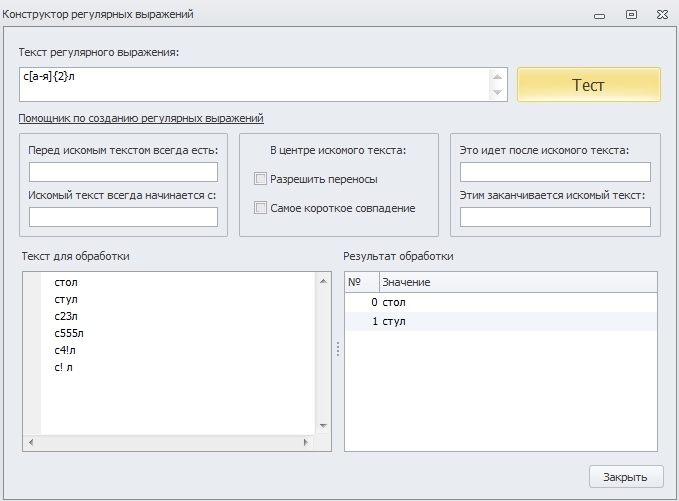
Для того, чтобы указать, что внутри будут только буквы, необходимо прописать таким образом:
c[а-я]{2}л
Так же можно задать определённую последовательность или набор символов, которые должны учитываться. Для этого используются квадратные скобки, внутри которых прописываются диапазоны, или наборы символов.
Для указания диапазонов используется тире между значениями. Для перечисления, символы просто прописываются в строку без каких либо разделителей.
[a-zA-Z1-5абв] - данная последовательность обозначает любую английскую букву в верхнем и нижнем регистре, числа от 1 до 5 включительно, а так же русские буквы а, б и в.
Регулярное выражение будет иметь такой вид:
с[тоу]{2}л
Мы обозначаем, что после буквы “с” идут 2 любых символа, указанных в квадратных скобках и данная последовательность найдёт слова стол и стул, но ему так же будут соответствовать последовательности букв “суул”, “сутл” и прочие.
Модификаторы:
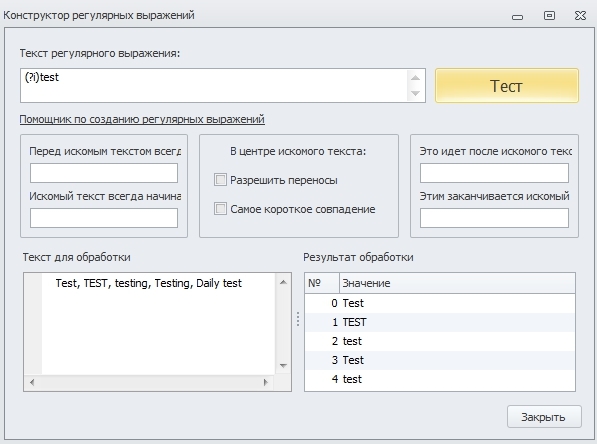
(?i) - включает нечувствительность выражения к регистру символов;
(?-i) - выключает нечувствительность выражения к регистру символов.
Используя данные модификаторы, мы можем указывать регулярному выражению, важен ли нам регистр символов при поиске совадений. Отключив регистр в начале регулярного выражения, мы его выключаем для всех последующих совпадений в строке.
Пример использования:
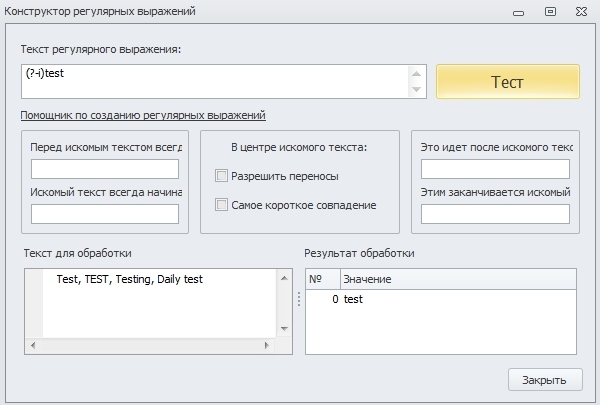
Так же бывают случаи, когда в одном месте регистр для нас не важен, а в другом важен.
Пример использования:
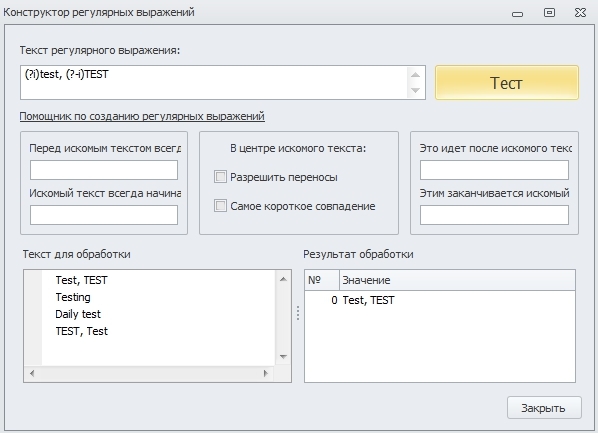
Данное регулярное выражение найдёт строку “Test, TEST”, т.к. у первой фразы включена нечувствительность к регистру и она находит все совпадения, но не найдёт “TEST, Test”, т.к. во второй фразе должно быть точное совпадение по регистру.
Модификаторы многострочного поиска:
(?m) - включает многострочный поиск
(?-m) - отключает многострочный поиск
Для того чтобы найти все строки, начинающиеся с не пробельного символа, подойдёт такое регулярное выражение:
(?m)^\S.*
Символы, которые должны экранироваться, для того, чтобы они учитывались в регулярном выражении как текст, а не как часть регулярного выражения (метасимволы):
^ [ . $ { *
( \ + ) | ?
При использовании данных символов в регулярном выражении, как части текста, они должны экранироваться знакоми \.
К примеру, если в тексте у вас должен находиться знак вопроса, он обозначается как \?
Рассмотрим детально основные случаи использования символов регулярного выражения.
.{5,10} - данному регулярному выражению соответствует последовательность от 5 до 10 любых символов, кроме переноса строки. Его можно использовать для обрезки текста до нужной длины, парсинга подстрок определенной длины, а так же для указания нужного количества неизвестного набора символов внутри текста.
а\d+а - в случаях, когда между искомым текстом, который известен, есть числа, состоящие из разного количества знаков. Данному регулярному выражению соответствует а1а, а23а, а459а и так далее.
а[2-5]{2,4}а - данное регулярное выражение возьмет текст, который будет начинаться на “а” и содержать внутри от 2 до 4 цифр 2, 3, 4 или 5 и будет заканчиваться на “а”. К примеру, а354а или а52а
К примеру, вам необходимо взять url сайта из следующей строки id="123" a href="www.site.com">, где номер id всегда меняется, а просто в теге a href находятся и другие урлы, которые не нужны.
Тестер регулярных выражений выдаст нам такой вариант:
(?<=id="123"\ a\ href=").*?(?=">)
но ему будут соответствовать только строки, айди которых равен «123». Т.к. нам нужно указать, что вместо 123 может быть любая последовательность цифр, мы заменяем их на \d+ и получаем следующее регулярное выражение
(?<=id="\d+"\ a\ href=").*?(?=">)
которое получит все строки, содержащие любые айди.
Что касается самого короткого совпадения в регулярном выражении. Нужно понимать, что под самым коротким совпадением понимается часть текста, которая начинается и заканчивается по условию, заданному в регулярном выражении.
Если мы возьмём строку a href="www.site.com"> a href="www.site2.ru"> и применим к ней регулярное выражение “(?<=a\ href=").*?\.ru(?=">)”, в ответе мы получим www.site.com"> a href="www.site2.ru вместо ожидаемого «www.site2.ru»
Почему поиск выдал нам не самое короткое совпадение? Происходит это потому, что регулярное выражение получило из текста первую часть, которая должна идти перед искомым текстом, т.е. “a href="”. Далее продолжило искать до тех пор, пока не нашло условие, по которому должна закончиться строка, т.е. “.ru”, после которого идёт ">
Для того, чтобы этого избежать, в данном случае можно использовать такую структуру регулярного выражения:
“(?<=a\ href=")\S+?\.ru(?=">)”
обозначить, что между частями искомого текста идёт непробельный символ, вместо любого символа, как было раньше
В случае же, если в части регулярного выражения может быть всё, что угодно - различной длины различный текст, или же он может вообще отсутствовать, можно в данном месте вставить последовательность «.*?»
Начало и конец строки
Для указания того, что искомое значение начинается с новой строки и (или) заканчивается в конце строки, подойдёт такое регулярное выражение:
^строка$
Часто такое обозначение помогает построить правильное регулярное выражение для поиска элементов на вебстранице.
В случаях, если мы ищем элемент на разных сайтах, и он может отображаться с разным регистром, к примеру: Строка, СТРОКА, строка. С точки зрения машины эти три значения будут различными, и найдется только то, которое прописано с учетом регистра.
Если нужно подготовить регулярное выражение, которое найдет все эти совпадения, необходимо прописать
(?i)^строка$
т.е. мы отключаем у регулярного выражения чувствительность к регистру и дальше уже прописываем само регулярное выражение. В таком виде найдутся все совпадения, независимо от регистра.
Если необходимо взять текст с вебстраницы, почты или файла, то нужно учитывать, что начало строки, обозначаемое, как ^ - это только начало первой строки текста, а конец строки, обозначаемое как $ - это только конец последней строки.
Остальные строки в тексте имеют переносы, т.е. все эти строки заканчиваются символом возврата каретки (\r) а начинаются символом новой строки (\n).
Для того, чтобы обозначить, что регулярное выражение должно начинаться и заканчиваться в пределах одной строки, мы можем прописать условие ИЛИ, которое обозначается как вертикальный слеш - |
Регулярное выражение выглядит так:
(?i)(\n|^)строка(\r|$)
Так же можно дополнительно использовать модификатор многострочного поиска, который каждую строку считает, как новую:
(?im)^строка
Подробнее об операторе ИЛИ
В регулярном выражении можно указать, что именно искать, используя оператор ИЛИ следующим образом:
1|2 (что будет обозначать выбор 1 или 2.)
Таким образом, мы можем проверять на странице наличие сразу нескольких текстов.
К примеру, Вам необходимо проверить на странице фразы "Привет", "Спасибо за регистрацию", "Приветствуем Вас", мы можем объединить все эти данные в одно регулярное выражение следующим образом:
Привет|Cпасибо за регистрацию|Приветствуем Вас
При таком построении, проверка наличия текста на странице получит один из указанных вариантов.
В случае же, если знак “ИЛИ” необходимо использовать не для всего регулярного выражения, как показано выше, а только для его части, эта часть должна находиться внутри скобок. Например:
Что (Он|Она|Они) дела(е|ю)т\.
Данное регулярное выражение найдет фразы "Что Он делает." "Что Она делает." и "Что Они делают."
Еще несколько примеров готовых регулярных выражений:
<.*?> - найдет все теги в искомом тексте;
[\.\-_A-Za-z0-9]+?@[\.\-A-Za-z0-9]+?[\.A-Za-z0-9]{2,} - найдет все email;
(\d{1,3}\.){3}\d{1,3}:\d{1,5} - получить айпи и порт;
(http|ftp|https):\/\/[\w\-_]+(\.[\w\-_]+)+([\w\-\.,@?^=%&:/~\+#]*[\w\-\@?^=%&/~\+#])? – получит урлы сайтов.
Всем спасибо, кто осилил данную статью, надеюсь она была полезна прочитавшим её пользователям и пригодится еще многим.
